

Share




Root-causing and troubleshooting issues across the IT environment is a hard task as today’s infrastructure and applications span on-premise and cloud environments, and are more elastic, dynamic and distributed in nature.
When an issue occurs, multiple teams receive an overload of alerts and need to jump from tool to tool to root-cause issues. Technological and organizational boundaries further complicate the process of piecing together a complete picture of what’s going on. This is quite a challenge considering that the modern IT environment is subject to constant change.
Sounds familiar? I bet you’re not alone.
Troubleshooting issues shouldn’t be a pain in the ass. At StackState we want to accelerate and simplify the way you root-cause issues across the IT environment. Issues across the IT environment can usually be traced back to changes. Having a complete change log of everything in the IT environment is therefore vital.
That’s why we built a Time Travel feature for applications and infrastructures at enterprise scale. Let me give you an introduction to this exciting capability of StackState's next-gen monitoring and AIOps platform.
Introduction to StackState’s Time Travel Capability
The foundation of our Time Travel feature is the full persistence of the 3T (Topology, Telemetry and Time) data model including all the historic changes and events. These 3 ingredients are a way to create a real-time replica of your IT environment to understand dependencies and visualize the health of every component in your environment.At StackState we've build our own versioned graph database to accommodate this model. It gives our users the ability to save each change and event as a snapshot and watch in detail how the various components of your environment were affected over time. Especially in enterprise scale environments, it is important to understand what state the whole system had when a certain issue occurred.
The Time Travel capability in StackState, will help you to:
- Immediately understand the cause and impact of each and every event over time. Now you can start fixing instead of searching for the cause.
- Root-cause issues by a single person or team. Finally say goodbye to war rooms and save valuable time and resources.
- Shorten your MTTR and deliver better customer experiences. Make sure you meet your application SLAs and deliver stable infrastructure.
Go Back in Time
OK – so how does it work? StackState is able to automatically discover, map and monitor your entire IT landscape. By default, StackState always displays the current situation, making the teams aware of what is happening now, but it also has a great memory. 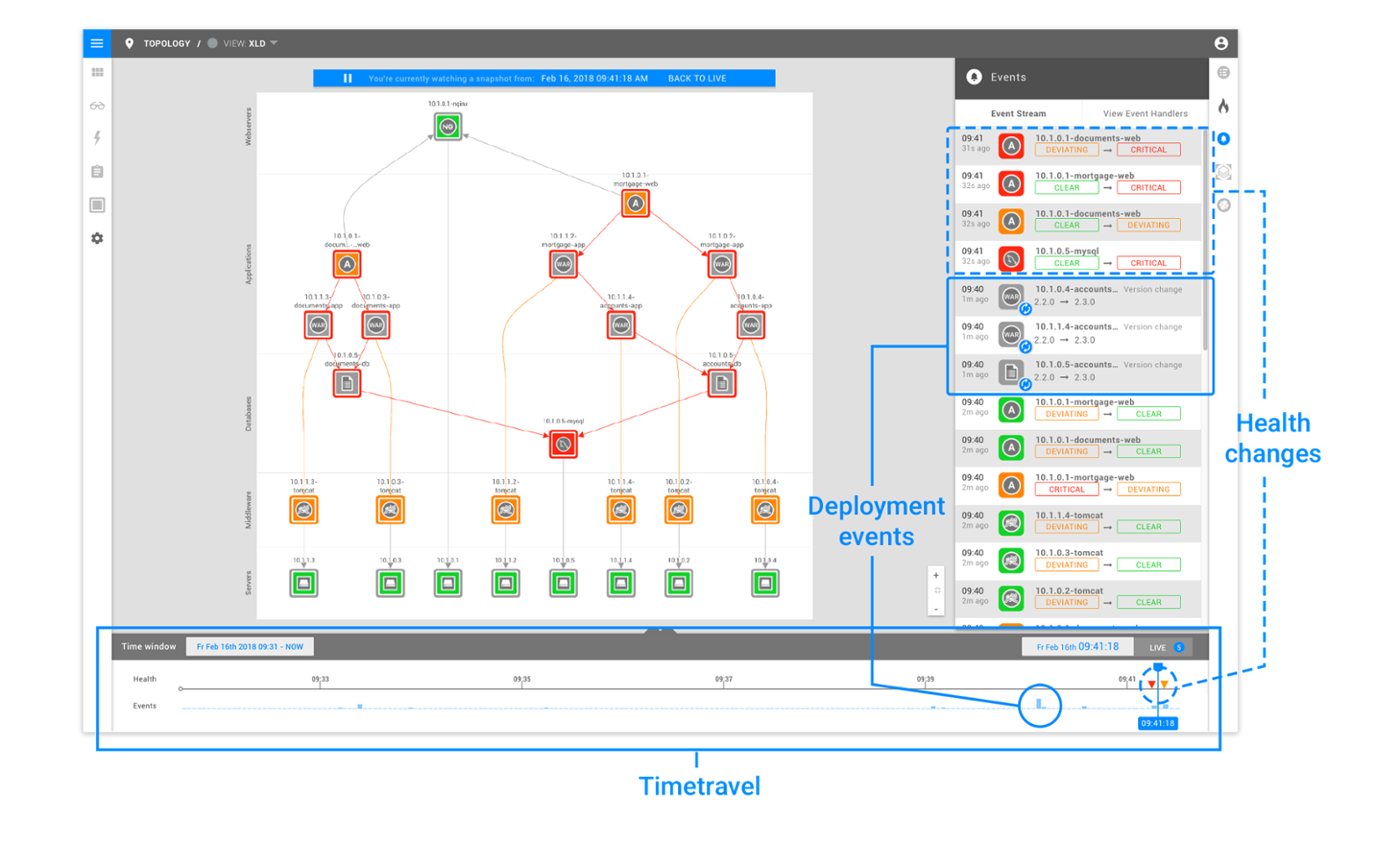
StackState keeps a record of all changes to your entire IT landscape and allows you to travel back in time. This makes it possible to root-cause and analyse failures and do interactive post-mortems, tracing back through all changes impacting your landscape.
The time travel functionality in action:
As you can see, the timeline below the topology view shows you what time the current view was taken and includes a record of the events and health changes that occurred at a specific moment in time. Clicking anywhere on the timeline allows you to travel to that point in time, displaying the events and metrics from the selected time range.
Imagine an IT landscape comprised of applications that all depend on each other, for instance in a containerized microservices architecture. An issue anywhere in the landscape will cause any number of dependent applications to fail. This situation is almost impossible to diagnose unless you know the dependencies between the components and are able to replay evolution over time. This topology and time travel capability are one of StackState's most fundamental features.
Root-causing issues doesn’t have to be a complicated process. Using a modern AIOps platform like StackState allows customers to spend their time building innovative features and delivering top-notch services instead of just keeping the lights on.
