

Share




What is Data Architecture?
As per TOGAF, Data architecture is a structured and comprehensive approach to data management and it enables the effective use of data to capitalize on its competitive advantages. As organizations embark on a digital journey by undertaking a large architectural transformation, it is equally important to understand and address data management issues. Some of the areas that need attention include:
- Data Management: This is a huge area but at a high level, it includes defining the master and the reference data and how the organization is creating, managing, storing, and reporting based on their data estates.
- Data Migration: With the advent of cloud, this is one of the first steps toward a data modernization journey. As applications (and hence data) move to the cloud, there will be a need to migrate the associated master, transactional (historical) and reference data.
- Data Governance: It involves identifying the organization structure, the key stakeholders to manage and own the data, having the right tools in place to enable transformation and ensuring the right skills are available. Data Quality is one such area, which often doesn’t get much attention or is overlooked.
Designing the right data architecture requires adherence to the data principles. With the data growing exponentially every day, these principles become even more crucial while embarking on a data transformation journey:
- Data is an asset: Being the foundation of all decision-making, data needs to be collected, transformed, and made available on demand.
- Data is shared: The end goal of data is to make it available to the business for decision-making. This needs to happen in a timely manner while ensuring that the data is accurate and can be trusted. The speed of collecting and processing data while ensuring a single source of truth is critical.
- Data is accessible: Businesses will need access to the data. This request needs to be adhered to in a timely fashion to enable users across the enterprise to take data-driven decisions. At the same time, the access privileges need to be clearly defined along with the mechanism for sharing sensitive data to prevent misuse.
- Data Trustee: Data owners, preferably business persons, should be involved to ensure data definitions are accurate and consistent while maintaining integrity.
- Data Security: This is one of the most important aspects to be considered while designing data architecture. Data privacy and compliance are crucial to an enterprise to prevent unauthorized access along with the protection of pre-decisional, sensitive, source selection-sensitive, and proprietary information.
- Common Vocabulary and Data Definitions: For data elements to be clearly understood across the enterprise, the definitions need to be consistent. This is also needed for the data exchange and the interface systems. Having a common definition will also allow business users to trust and use the data.
Components of Data Architecture
The components that constitute data architecture have evolved with time as technology has changed and evolved. According to BMC, some of the components of a modern data architecture include:
- Data pipelines: Data pipelines define the way how the data will be ingested, stored transformed, analyzed, and delivered. Data pipelines also need to be orchestrated to run in batches or stream data continuously.
- Cloud storage: Cloud storage allows for cheap and durable storage for all enterprise data. Data lakes provide a common storage point for data coming from various sources.
- Cloud computing: For organizations already on their cloud journey, the use of no code ETL tools (ADF, Glue), big data and spark processing engines is mainstream.
- API: APIs are one of the most common ways of data sharing, allowing ease of integration, security, and automation.
- AI and ML models: Machine learning models are now embedded at all levels, into all aspects of data and they are not just limited to use by the business for decision-making. They are being widely used for labeling, data collection, ensuring data quality, etc.
- Data streaming: The business needs are moving toward real-time and streaming-data use cases, which require continuous ingestion and making the data available for analytics in real time.
- Container orchestration: Containers become a core piece of microservices-based design and architecture. They allow for easier packaging and are secure and easy to deploy. However, the overall lifecycle management can be a challenge sometimes, especially in a large-scale enterprise.
- Real-time analytics: The paradigm is shifting towards event-driven architectures and the ability to deliver real-time analytics. The ability to perform analytics on new data as it arrives in the environment has become one of the core components of modern data architecture.
Why do we need a Data Architecture Model?
Data architectures have continued to evolve. In the past, they were less complicated, mainly due to structured data from transactional systems. Analytical data was mainly stored in the data warehouse as a star schema with smaller marts sometimes built for individual business units.
With the advent of big data leading to semi-structured and unstructured data, the storage and compute mechanisms were involved, and data lakes (and now lakehouse) came into being and the ingestion mechanism started to shift from ETL to ELT.
The next shift came in terms of stream processing and event-driven architectures, leading to real time and more complex data architectures. Cloud brought another dimension where the data could be stored and processed comparatively at a lower cost but not without concerns around data compliance and security.
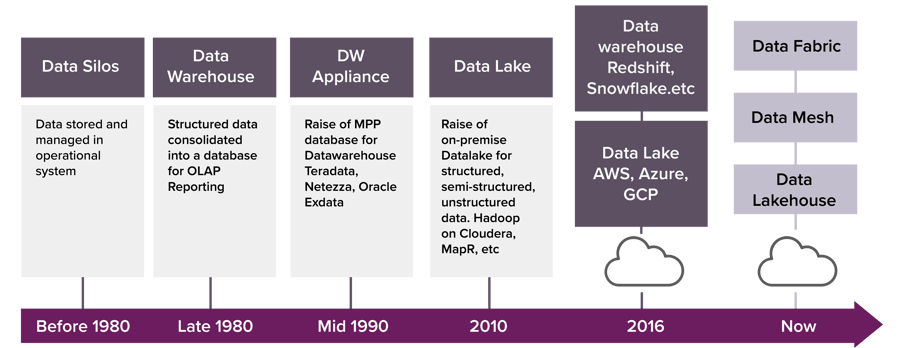 Image source: Medium
Image source: Medium
Machine learning and advanced analytics have become mainstream and almost all enterprises now want it to be incorporated into their day-to-day decision-making for improving business processes. However, this is not possible with the legacy data platforms and the limited computation they (may) have. The traditional monolith and the legacy systems are not equipped to provide the necessary infrastructure to run the large-scale machine learning models and to fully leverage the advanced analytics capabilities. Examples of modern data platforms include the public cloud providers, like Microsoft Azure, AWS and Google or the on-premise platforms, like Cloudera CDP. However, the underlying principles for these data architectures remain the same.
In the current era of data overflow, one of the key challenges is to make sure the data is made available and accessible across workloads. Data discoverability, governance and reliability are some of the key challenges today and the data management solution needs to address these challenges/concerns in a hybrid, multi-cloud ecosystem.
The architecture models help to address the above challenges and enable organizations in better decision-making. The most popular ones are listed as follows:
- Data Fabric
- Data Mesh
- Data Lakehouse
So, what is Data Fabric?
Data Fabric is built on top of the modern data warehouse and provides the capability for enterprise data integration approach in a controlled way. This data is made available via self-service. It imbibes the principles of data management to provide quality, security, governance, and cataloging.
Data fabric simplifies database access by encapsulating the complexities caused by the number of applications, data models, formats and distributed data assets found in an enterprise. The user can access the data without knowing the data's location, association, or structure.
The core pillars of Data Fabric are formed around metadata (which is also a core data architecture principle), a robust data integration backbone and a semantic layer. Data fabric relies heavily on metadata to achieve the goal of delivering right data at the right time. The metadata should be able to identify, connect and analyze the data for the various methods, including batch, streaming, messaging, etc. The following diagram shows the key pillars of a data fabric as per Gartner.
 Image Source: Gartner
Image Source: Gartner
Data Fabric Adoption
The greatest challenge in implementing data fabric solutions is that data exists in silos. The wide variety of databases, data management policies and storage locations make it difficult to integrate. A fabric solution must obviously be able to harmonize all these differences. Most enterprises use a data virtualization tool to achieve the same. However, harmonization and unification through virtualization always create a risk and may have performance and cost implications as well, due to data transfer between hybrid or multi-cloud boundaries.
What is Data Mesh?
Zhamak Dehghani states in her book, “Data Mesh is a decentralized sociotechnical approach to share, access and manage analytical data in a large scale, complex environment.” It is built around the core principles of decentralizing the data, providing domain ownership, self-service infrastructure as a platform and treating data as a product, which is then shared across the enterprise using federated computational governance. The fundamental shift in the value system for a data mesh is that it moves from treating data as an asset to be collected to data as a product to serve the customers. Data mesh is built on two design approaches:
1. Outcome Focused:
Data product thinking – Mindset shift to data consumer point of view- Data domain owners responsible for KPIs/SLAs of data products
- Same technology mesh and data domain semantics for all
- Remove the ‘man in the middle’, by making data events directly accessible from systems of record and providing self-service, real-time data pipelines to get data where needed.
2. Rejects Monolith IT Architecture
Decentralized architecture- An architecture built for decentralized data, services, and clouds
- Designed to handle events of all types, formats, and complexities
- Stream processing by default, centralized batch processing by exception
- Built to empower developers and directly connect data consumers to data producers
- Security, validation, provenance and explainability are built-in
Principles of Data Mesh
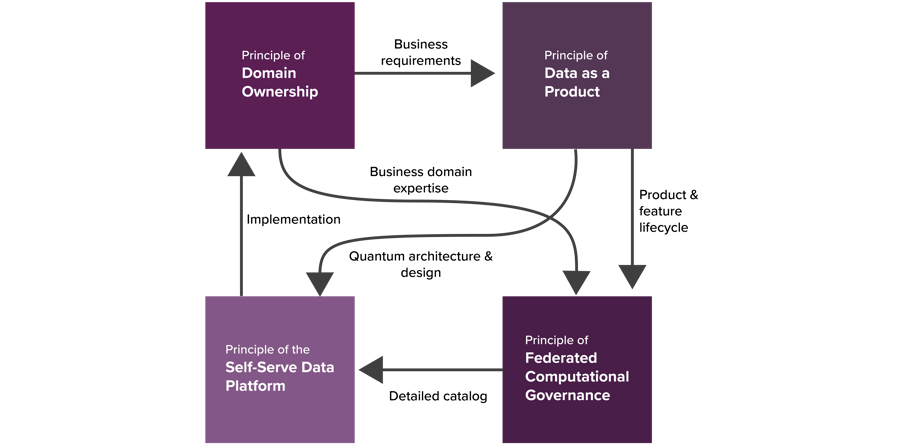
Image Source: Medium
Principles of Data Mesh
1. Principle of Domain Ownership: Decentralize the ownership of analytical data to business domains closest to the data – either the source or its main consumers.
2. Principle of Data as a Product: Domain-oriented data is shared as a product directly with explicit data users. This data as a product adheres to the set of usability characteristics, including discoverability, addressability, comprehensibility, security, etc.
3. Self-Service Data Platform: Consists of self-service data platform services that empower cross-functional teams to share data. This helps in reducing cost, automation of governance policies and abstraction.
4. Federated Computational Governance: This is a data governance operating model based on the federated decision-making and accountability structure. This model heavily relies on codifying and automating the policies at a fine-grained level for every data product via the platform services.
Data Mesh Adoption
To qualify as a suitable candidate for data mesh, organizations need to evaluate themselves across the seven dimensions as shown in the image alongside.
What might make it difficult for most organizations is that they need to score Medium (M) or High(H) in ALL the categories.
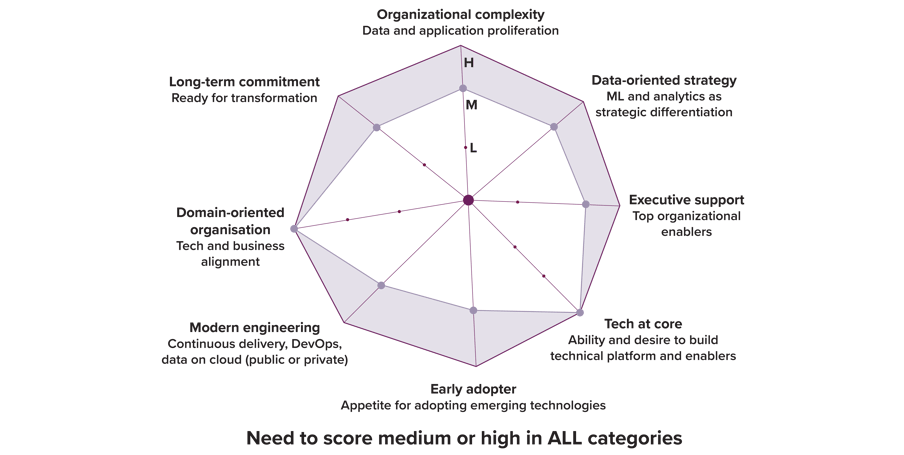 Image Source: Data Mesh by Zhamak Dehghani
Image Source: Data Mesh by Zhamak Dehghani
Data Lakehouse
Data lakehouse, as the name suggests, is built on top of the data lake, and is optimized to provide the scale of the data lake, along with the integrity of the data warehouse for both batch and streaming data. According to databricks, a data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data. Lakehouse implements data structures and data management features similar to those in a data warehouse, directly on low-cost storage like the one used for data lakes.
A data lakehouse is an extension of the data lake and should be able to support all data formats, including structured and unstructured data. This means that businesses that can benefit from working with unstructured data (which is pretty much any business) only need one data repository rather than requiring both warehouse and lake infrastructure.
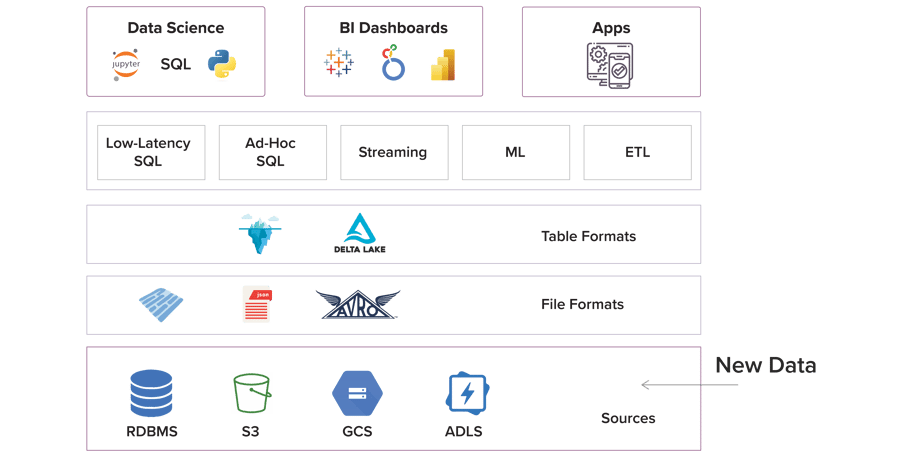 Image source: Dremio
Image source: Dremio
Lakehouse is built on some of the following core principles:
- Metadata layer - Acts as a sort of "middleman" between the unstructured data and the data user in order to categorize and classify data, allowing it to be cataloged and indexed. This layer allows for support for streaming I/O (eliminating the need for message buses like Kafka), time travel to old table versions, schema enforcement and evolution, as well as data validation.
- Smart Analytics layer – The lakehouse is an optimized SQL-like Query engine for execution on the data lake, allowing for automated integration of data. A data query can be done from anywhere using any tool, in some cases using a SQL-like interface to query structured and unstructured data alike. This is achieved by caching hot data in RAM/SSDs (possibly transcoded into more efficient formats), data layout optimizations to cluster co-accessed data, auxiliary data structures like statistics and indexes, and vectorized execution on modern CPUs.
- Access for data scientists and machine learning tools – The open data formats used by data lakehouses (like Parquet), make it very easy for data scientists and machine learning engineers to access data in the lakehouse. It also allows citizen data scientists to use unstructured data together with AI and machine learning. Lakehouse also allows for audit history and time travel, helping with ML use cases.
Data Lakehouse Adoption
While data lakehouse aims to provide the best of both worlds, the scalability of data lakes and the integrity of data warehouses, some areas that need to be thought through while implementing this approach, including the complexity of the solution, governance and performance. These are cost-effective solutions and allow the storage of structured and unstructured information in one place before using the metadata layer on the top of the data lake, like APACHE HUDI, ICEBERG, and DELTA.
Conclusion
Data architecture is a blueprint for managing data. Regardless of any framework, the end goal remains the same. The shift is now more towards providing accurate and timely data in a secured and governed way to business users to enable data-driven decision-making rather than just collecting and storing data. Data Strategy becomes a key activity in determining the way forward.
Implementing any of the above architectural styles depends on the maturity of the organization. It is more about the processes and cultural changes than the technology. There is no template, or a one-size-fits-all approach, which can be replicated across organizations.
Also, there is a lot of overlap between these styles, and they can be used together as well, rather than as standalone solutions. They are not mutually exclusive. The key pillars of all architectural styles are similar. Automatic integration of data sources, a well-defined catalog, and ease of access to useful and relevant data in a timely manner are the principles across all these frameworks. Organizations are at liberty to use one or more as they deem fit.
References:
Demystifying Data Platform Architecture on Medium
Data Lakehouse Glossary on Databricks
What is a Data Lakehouse? on Forbes
Data Fabric Architecture on Gartner
TOGAF Chapter on The Open Group
The Next Generation of Data Platforms on Medium
Data Fabric Architecture on Gartner