

Share




Microservices Architecture in the Context of a Modern Data Stack
Microservices are now a core part of most, if not all the application development. However, with the recent evolution in data-related technology and frameworks, e.g. Data Mesh, microservices architecture is now becoming mainstream and part of the modern data architecture design.
Microservices architecture is a software design pattern that structures an application as a collection of loosely coupled services (e.g. by business functions). In the case of data processing, it could be a pipeline step. Microservices design allows for these services to be developed, managed and deployed independently of the other services in the pipeline.
In a modern data stack, this is an approach to designing a data processing workflow, which includes processes such as data ingestion, data storage, data transformation, or data delivery by breaking down these processes into a collection of small, independent, and highly specialized services to handle the entire data processing.
The microservices are designed to be loosely coupled, providing greater flexibility and agility in managing the data processing system, as new services can be added or removed as needed without disrupting the overall system. It also provides developers with the flexibility to use the technology stack they are comfortable with, and which might be a better fit for their specific service.
The Microservice Data Management Patterns
- The Database-per-Service pattern
The database per service allows decentralization and provides more flexibility. It allows for independent scaling and the data schema changes can perform without any impact on other microservices. Separating databases means that each DB can be individually designed based on the workload and nature of data. - Shared Database pattern
A shared database allows for a logical separation between the microservices with them sharing the same physical instance. - The CQRS pattern
The CQRS allows for separate database instances for querying and issuing commands. This is more suitable in a scenario where there are more reads than writes. - The Event Sourcing pattern
Event Sourcing persists and aggregates as a sequence of events. - The Saga pattern
Saga allows the implementation of business transactions spanning across multiple services with each local transaction updating the database and triggering the next local transaction. In case of a failure, saga executes a series of compensating transactions to roll back the changes.
How Can Microservices Help to Design a Modern Data Architecture?
The first step is the identification of the business requirements for the data architecture, including identification of data sources, the nature, format, and frequency of data, and data processing requirements, which may include steps for Data Quality, Master Data management, Data Cataloging, etc. Once this is done and the processing workflow is defined, each step in the workflow is broken down into a microservice and containerized allowing it to be managed, deployed and scaled independently. Some of the common elements which need to be a part of all the microservices are observability, data security, and any specific compliance and privacy rules.
As you will see below, while designing a data platform architecture for an enterprise, multiple aspects need to be considered. As we move from the left to the right, a fully automated data platform may consist of multiple steps for its data processing pipelines. A simple batch ingestion pipeline, for instance, will use the batch ingestion framework, a data quality and catalog service, require aggregation before loading into the warehouse, and will need to be automated, monitored, and orchestrated for failure, etc. Each of these hops can be its microservice, with each service having its own storage, computing, and processing components.
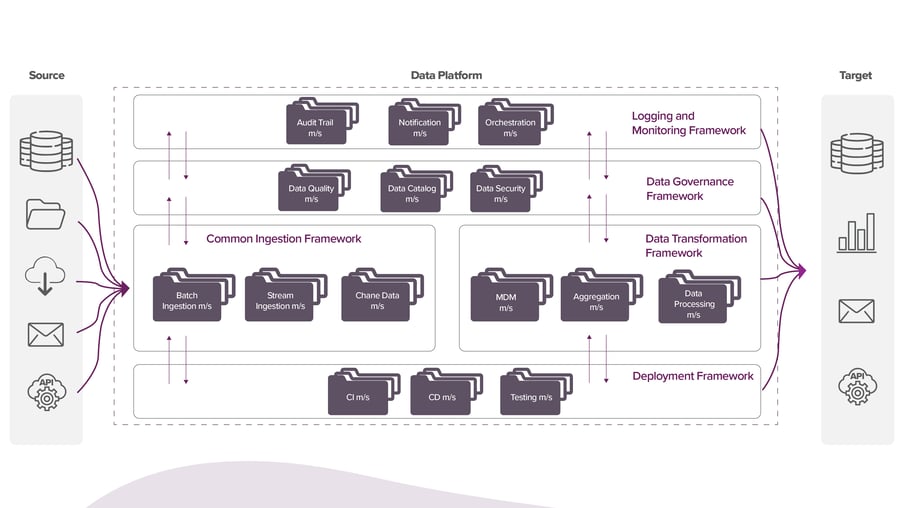
Challenges
As the data moves from the producers to the consumers, all the hops of the data pipeline, although they are separated via microservices, must run seamlessly as part of the overall execution. While this sounds obvious, this raises some obvious design aspects which need to be thought through:
- How do you ensure consistency between the different services as there is a possibility of the data being duplicated across services?
- In case of a failure, how do you roll back the entire transaction which could span multiple services?
- How are the changes in the data definition communicated across the services (both forward and backward) and how to manage ACID vs eventual consistency?
- How do you scope and prioritize the issues (across teams) in case of a failure?
- How do you ensure code and data isolation as the overall engagement may contain multiple services and projects?
Microservices are about data decentralization. They should have their own data while also being able to interact and share data. The above questions need to be answered and carefully planned before the actual implementation. More microservices lead to added complexity and clearly there is a trade-off that needs to be made when deciding the right number to allow for decentralization and modularity, while making sure team size, testing and debugging, and team coordination don’t go out of hand.
You might also be interested in GCP Certifications | AWS Certifications
Cloud service providers, like Azure, AWS, and GCP are big enablers in allowing for a microservices architecture. The multitude of cloud services for ingestion, storage, computation, deployment, orchestration, etc. allows for a flexible design for microservices and event-driven architecture while implementing service discovery, security and compliance, and automated deployments. Within AWS for instance, you can design microservices either using AWS Lambda or using Docker Containers with AWS Fargate.
A good example of a serverless microservice for an e-commerce application can be seen below. Similar architecture patterns and designs can be done using Microsoft Azure and GCP as well. 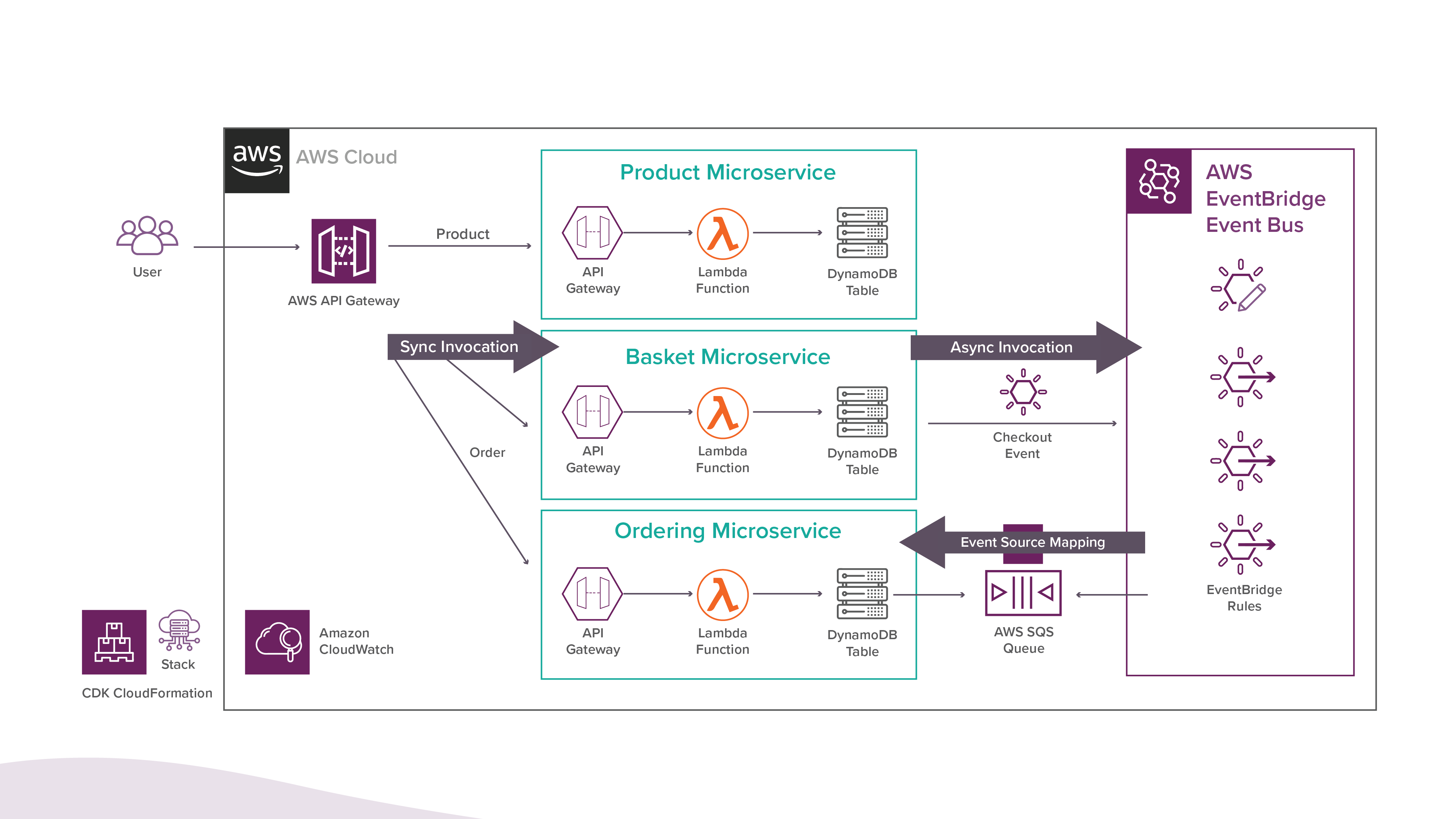
Image Source: Medium
Conclusion
Microservices architecture is well-suited for modern data platforms and more suited for large enterprises with multiple functions which require processing and managing large volumes of data in real time. This is also suitable for Event-Driven architectures, which allow data to be consumed as events before it is requested. Microservices design allows for more granular control over different parts of the platform, making it easier to scale and maintain. The use of cloud, and specially containerization, has made it easier to develop and deploy microservices.
The design and assessment of whether microservices design is the right fit for an organization and its data platform needs to be made. A lot of effort has to be made in the design, development, and maintenance of the design against the cost and complexity of implementation. For some smaller organizations, a monolith might just fit the bill.
References
Microservices Database Management Patterns and Principles
Getting Data to Data Lake from Microservices Part 1: From Databases
Microservices Architecture Patterns Index
AWS Serverless Services for Microservices Architectures
Ingesting Terabytes of Data Every Day Using Microservices Architecture at MiQ