

Share




Imagine this. You have built a website to sell your company’s products. After a few months of hard labor, the application finally goes live. Of course, the application has been thoroughly tested. It all started with Unit Tests. First on the local machine and after the engineers filed a Pull Request a whole series of checks were executed. Each quality gate passed successfully and a fully automated pipeline successfully deployed the application on a cloud environment. But you went that extra mile. Performing load tests, security tests, pen tests, and smoke tests. And finally, to make sure you have the least downtime possible when the sh*t hits the fan, you created and implemented failover scenarios and disaster recovery plans. Now you are all set. Let the sales begin!
And then… everything goes black. The data center is down, and the failover you carefully set up does not work as expected. And, after a few hours of stress, when the data center has recovered, the way back does not go well.
This scenario is not something that only exists in a fantasy world. It is a real scenario. Things happen and you need to be prepared. And the truth is, you cannot prepare for everything. When you operate a business in the cloud (but also in your own data centers) you need to embrace the fact that things can go wrong. The question is, how well can you deal with that.
Chaos Engineering
When Netflix moved to the cloud in 2011, they wanted to address the fact that it lacked sufficient resiliency tests in production. To make sure they were prepared for unexpected failures in production, they created a tool called Chaos Monkey. This tool caused outages and breakdowns on random servers. By testing these “unexpected” scenarios they could validate and learn if their infrastructure could deal with and recover from failure in an elegant manner. Without deliberate thoughts, Netflix introduced a whole new practice. Chaos Engineering.
Breaking servers was one way to test this, but quickly other scenarios became relevant. Slow networks, unreliable messaging, corrupt data, etc. Not much later, other Tech companies, especially those that were running large-scale and complex landscapes in the cloud also adopted similar practices. These practices, where the mindset shifts from expecting stable production systems, to expecting chaos in production are called Chaos Engineering.
Chaos Engineering is a concept that uses hypotheses and experiments to validate the expected behavior of complex systems. This way you can grow confidence in the reliability and resilience of these systems.
Why Chaos Engineering?
Chaos Engineering lets you compare what you think will happen to what actually happens in your systems. You literally “break stuff ” to learn how to build more resilient systems. But there are a few important differences. Therefore you can look at Chaos Engineering as a test practice. But there are important differences. First of all Chaos Engineering, when done right, is also done on production systems. Secondly, with Chaos Engineering you don’t really test for failure. You test beforehand, and by conducting Chaos experiments you try to prove that the assumptions you made in your test scenarios and architecture are actually valid and working.
With the rising complexity of our infrastructure, due to software architectures like Microservices, but also the “connected” systems we build nowadays, the traditional QA approach is not sufficient anymore. There is simply too much that can go wrong, and with the dynamic nature of the software and infrastructure stack, this can be different every day. With Chaos Engineering it all starts with a hypothesis. And based on the hypothesis you define and conduct experiments to prove that your hypothesis is working.
For example, “When the external payment provider I use is unavailable, my customers get the option to pay afterward and continue their checkout process”.
The 5 principles of Chaos Engineering
To start with Chaos Engineering you can use this simple plan to go through a number of steps that I will explain in further detail in the rest of this article
Before we go there it is good to understand that Chaos Engineering is not something you can do on a rainy Sunday afternoon. Chaos Engineering needs careful planning and impact analysis. You need to understand what happens if your hypothesis is wrong. You also need to understand “the blast radius”. In other words, what breaks if things do not work out as you planned. And linked to that, are there people available during the execution of the experiment?
The website Principles of Chaos Engineering describes 5 principles that you should consider when doing Chaos Engineering
- Build a hypothesis around steady-state behavior
This means you should focus on what is visible to the customer. Not the internal working of a system or things you can only influence when you know the inner workings. Focus on the steady-state and the metrics that belong to a steady-state
- Vary real-world events
Prioritize events based on expected frequency. Consider everything that can influence the system’s steady-state. For example, disk failure, servers dying, or network outage
- Run experiments in production
Simulation and sampling is great, running on real-world data and metrics is better. Try to run on production whenever possible. Of course, this requires careful planning and involvement of people. Usually, this is done on so-called game days, when people are ready for the “game”. When you start with Chaos Engineering, it might be a better idea to validate your hypotheses on non-production systems. Start there, to get an idea of what to expect and what you should measure. The production introduces an extra level of complexity and control because you need to make sure your users are not impacted.
- Automate experiments to run continuously
As with almost everything in DevOps. Automation is key. Running experiments and gathering metrics is time intensive and hard work. Make sure you automated this so you can run the experiment repeatedly. Due to the nature of Chaos Engineering things can happen over time.
- Minimize blast radius
Experimenting in production has the potential to cause unnecessary customer pain. So be mindful of that. Make sure there is room in your error budget or prepare for some issues. There must be an allowance of a negative impact but keep the fallout of experiments minimal.
How does it work?
Chaos Engineering involves going through a number of steps. These steps are followed for each new experiment. As I described before, it is important to plan this carefully. Because many of the chaos experiments are executed on production systems, you can easily break things that have customer impact. Often companies choose to organize so-called Game days. These days, people know that chaos experiments will be executed and can be on standby or be extra careful to monitor the systems for strange behavior. When running chaos experiments you can follow this structure:
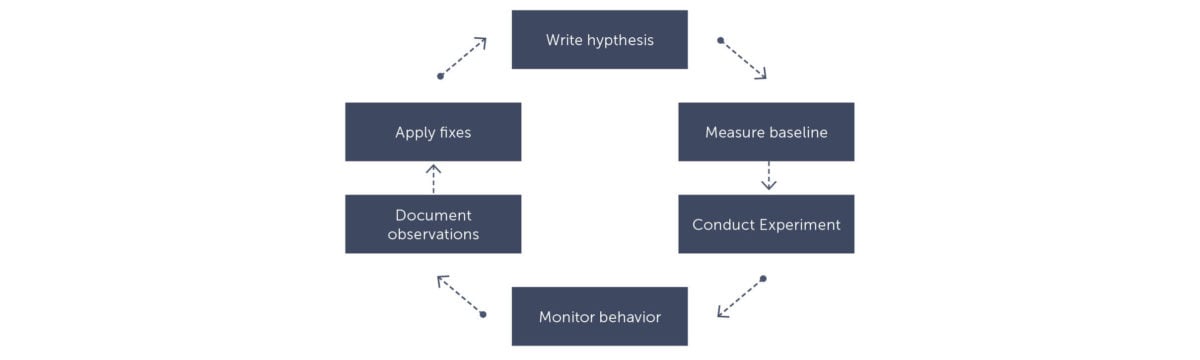
Write a hypothesis
With Chaos Engineering it starts with a hypothesis. This is important! It is not a test. For example, the hypothesis “The payment service should respond”, is not a valid hypothesis. This is something that you should already have tackled in your test suite Chaos Engineering is about making sure your application becomes more resilient. You should already be quite certain that your system can deal with unknown situations and your hypothesis should build on that. For example. “When the payment service goes down, we offer our customers an alternative way of payment”. Think about the user. How can the user continue its journey with the least impact? A good example that Netflix uses when the login functionality stops working, is that they offer services for free, without logging in. That way, users can still do what they need to do.
Measure baseline behavior
Before you run any experiment you should be aware of the baseline behavior. How does your system normally respond? In other words, can you recognize anomalies? You should have a good idea of the baseline because otherwise, you can draw the wrong conclusions. For example, if you run an experiment to prove that your response times will stay the same as “usual”, you should know what usual is. Maybe this varies throughout the day due to traffic on your site. F you run an experiment in that timeframe you might see strange things that are caused by other factors than your experiment.
When you think about creating the baseline, you should think of metrics and user metrics that are important to look at in the light of the experiment and hypothesis you are working on. Not everything is relevant at the same time.
Conduct experiment
When you created the hypothesis and baseline, you can start running an experiment. Running an experiment is causing the behavior that would disproof your hypothesis. So slowing down traffic, bringing a service down, shutting down or killing containers, etc. There are a number of tools that can help you in running Chaos experiments. Many of them are targeted at virtual Machines or a Kubernetes cluster and cause havoc on the infrastructure layer. Of course, you can also write your own scripts or tools that can help you with your experiments.
The most important tools that you can use are:
Monitor the resulting behavior
When you conducted the experiment, it is time to look at the metrics again. What do you see? Do you see the expected behavior of your system? Is the hypothesis valid? When you see that the system does not behave as expected try to gather as much information as possible why this is the case. Also, make sure you keep the blast radius and real user impact in focus.
Document the process and observations.
After the experiment, you either proved or disproved your hypothesis. Make sure you document the process you executed and especially when you found that your hypotheses failed, make sure you document your learning. Maybe do a blameless learning review to find out what happened and write the learning review for future use.
Identify fixes and apply them
When you found that your hypotheses did not work, apply the necessary fixes and automate the experiment. Make sure you can run the experiments multiple times. Maybe even on a schedule. Systems change and environments change, and you need to validate your hypotheses over and over again.
How can I get started with Chaos Engineering?
Getting started with Chaos Engineering is something you can do any time as long as you take the user impact and blast radius into account. A common way to introduce chaos is to deliberately inject faults that cause system components to fail. The ultimate goal of Chaos Engineering is to create a more resilient and reliable application. With Chaos Engineering practices you need to test and validate that your application is indeed more resilient. Architectural patterns like circuit breakers, failover, and retry can really help to make your application more robust. Then, after you have built your application you need to observe, monitor, respond to, and improve your system’s reliability under adverse circumstances. For example, taking dependencies offline (stopping API apps, shutting down VMs, etc.), restricting access (enabling firewall rules, changing connection strings, etc.), or forcing failover (database level, Front Door, etc.), is a good way to validate that the application is able to handle faults gracefully.
Important notice is to start small. Start by defining a hypothesis and a very small experiment and go through the different steps that I described above. To define your first hypothesis you should look at things you expect to go right but where you never actually looked at. A good source of inspiration is a keynote by Adrian Cockroft Adrian Cockroft's Keynote. In this keynote, he explains some basic things that go wrong. For your convenience, I listed a number of these categories and thongs that can go wrong
Infrastructure Failures
| Device Failures | Disk, power supply, cabling, circuit board, firmware |
| CPU failures | Cache corruption, Logic bugs |
| Datacenter failures | Power, Connectivity, cooling, fire, flood, wind, quake |
| Internet Failures | DNS, ISP, internet routes |
Software stack Failures
| Time Bombs | counter wrap round, memory leak |
| Date bombs | Leap year, leap second, epoch |
| End of unix time | |
| Expiration | Certificates timing out |
| Revocation | License or account shut down by supplier |
| Exploit | Security failures e.g. Heartbleed |
| Language bugs | Compiler, interpreter |
| Runtime bugs | JVM, Docker, Linux, Hypervisor |
| Protocol problems | Latency dependent or poor error recovery |
Application Failures
| Time bombs (in application code) | Counter wrap around, memory leak |
| Date bombs (on application code) | Leap year, leap second, epoch, Y2K |
| Content bomb | Data-dependent failures |
| Configuration | Wrong config or bad syntax |
| Versioning | Incompatible versions |
| Cascading failures | Error handling bugs |
| Cascading overload | Excessive logging, lock contention, hysteresis |
| Retry storms | Too many retries, work amplification, bad timeout strategy |
Operations failures
| Poor capacity planning |
| Inadequate incident management |
| Failure to initiate incident |
| Unable to access monitoring dashboards |
| Insufficient observability of systems |
| Incorrect corrective actions |
Summary
Chaos Engineering is fairly new to many people. Although It has existed for a number of years, it is not yet embraced by a broad audience. That is a shame because Chaos Engineering can really help you to build more resilient systems. By defining hypotheses and conducting experiments to prove your hypotheses you can test your system to deal with unexpected situations. There are many small experiments you can execute on your system so getting started should be very simple. However, always take the potential user impact and blast radius into account and carefully plan your game day.