





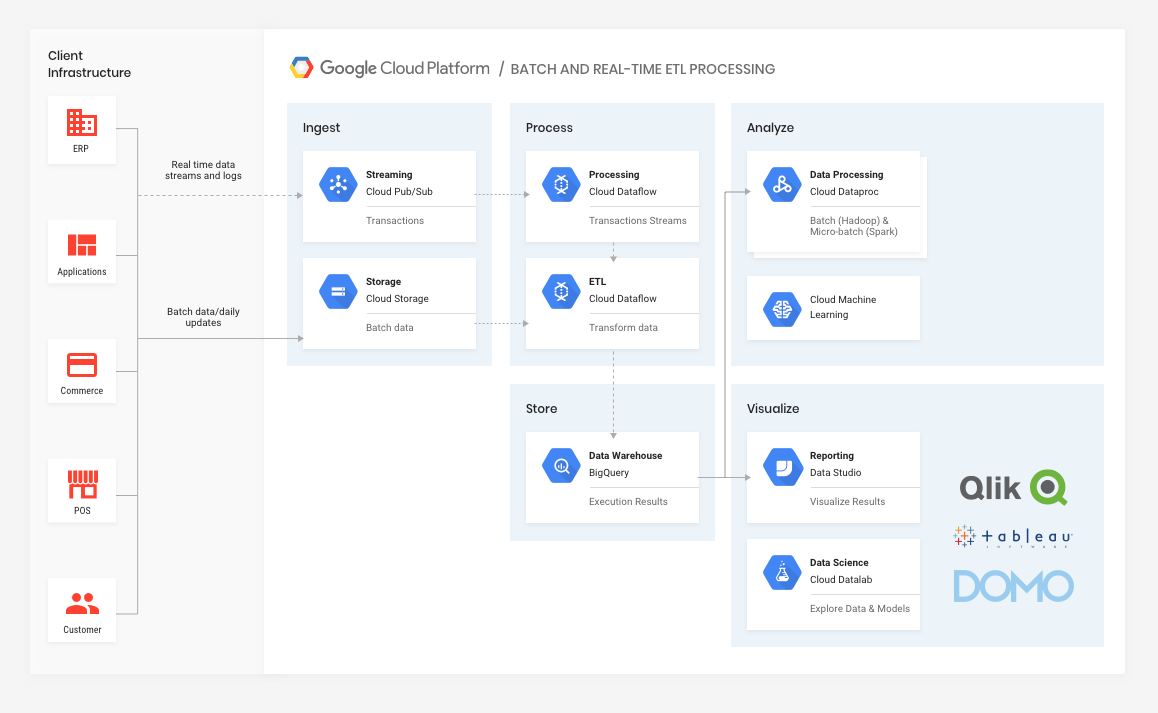
This, in turn, enables them to start moving from large-scale batch workloads to micro-batch workloads as their back-end infrastructure modernizes over time. It also gives them the ability to carry out data processing and transformation upon ingest (Cloud Dataflow is a fully-managed stream and batch data processing service based on Apache Beam).
Over time, as back-end systems allow, the retailer would be able to take advantage of real-time ingest (via Cloud Pub/Sub), and continue to leverage the processing and storage capability in the same data warehouse as the ETL data.
The great thing about the GCP stack is that it is a highly modular fully-managed service, so any enterprise could initially migrate ETL, data processing, and visualization to the cloud for infrastructure cost savings. Over time, and as capability within the enterprise grows (technology and human), it could leverage real-time data streaming into the same stack. Here are some key features and products to highlight:
Cloud Pub/Sub
Pub/Sub can be seen as a message-oriented middleware in the cloud, providing a number of high utility use cases, specifically in our case asynchronous workflows and data streaming from various processes, devices, or systems. It enables the real-time ingest of information for processing and analysis.
Google Cloud Storage (GCS) and Storage Transfer Service
GCS is a unified object store and simply acts as a staging point for data being loaded by various back-end systems before processing. This staging point creates an opportunity to ensure data can be standardized before downstream services start processing.
The transfer service (not shown in architecture) provides a mechanism to drop data into cloud storage, for example for one-time transfer operations, recurring transfer operations, as well as periodic synchronization between data sources and data sinks. It removes the headache of manually managing loading of batches, etc., adding to the level of automation between internal and cloud-based processing.
Google Stackdriver
While not critical to the operation of data processing and analysis, Stackdriver (not shown in architecture) allows everyone to sleep better at night, by providing very powerful monitoring, logging, and diagnostics, ensuring all the data processing workloads and any downstream applications are healthy and performing optimally. Given that monitoring can also be embedded into your own infrastructure, it provides a holistic view of the data supply chains within your business.
Cloud Dataflow
Cloud Dataflow is a service (based on Apache Beam) for transforming and enriching data in stream (real-time) and batch (historical) modes with equal reliability and expressiveness. It provides a unified programming model and a managed service for developing and executing a wide variety of data processing patterns, including ETL. Cloud Dataflow unlocks transformational use cases across industries, including:
- Clickstream, Point-of-Sale, and segmentation analysis in retail
- Fraud detection in financial services
- Personalized user experience in gaming
- IoT analytics in manufacturing, healthcare, and logistics
Google contributed the Cloud Dataflow programming model and SDKs to the Apache Software Foundation, thus giving birth to the Apache Beam project, which is fast becoming a de facto tool in the data processing space. Jan 2018 - Apache Beam lowers barriers to entry for big data processing technologies
BigQuery
Google BigQuery is a cloud-based big data analytics web service for processing very large read-only data sets. It is effectively a fully-managed data warehouse in the cloud. BigQuery was designed for analyzing data on the order of billions of rows, using a SQL-like syntax. It runs on the Google Cloud Storage infrastructure and can be accessed with a REST-oriented API.
Data from BigQuery can be ingested by various applications for regular or ad hoc workloads, e.g. end-of-day reporting using tools like Dataproc (GCP’s fully-managed Hadoop or Spark service), reporting in DataStudio (or other BI / visualisation tools), or for emerging data science initiatives, using DataLab (which uses the open-source Jupyter core).
Alongside a fully managed service, there are a couple of benefits with Google’s approach to infrastructure. Firstly, almost every GCP service has an open-source core, thus giving every customer the freedom to choose to migrate off GCP at any time, into any other infrastructure of their choice (though they would likely need to hire a small army of DevOps and CRE’s to manage it). Secondly, GCP includes a free tier; for example BigQuery has two free tiers: one for storage (10GB) and one for analysis 1TB/month, thus encouraging its use for prototyping or testing.
Conclusions
We’re excited by the sheer variety of data innovation options ahead of many of our clients and prospects, some of which could drive the next 5-10 years of landmark growth for them. Not just in terms of data processing and vizualisation, but also in terms of creating real-time data supply chains at the heart of their businesses. Ultimately, that is our mission.
If you’re thinking you need help in any of this, we’d be happy to explore the options relevant to your business.