

Share




When Harvard Business Review called it, “The Sexiest Job of The 21st Century,” data scientists were the magical all-rounders with machine learning expertise, domain knowledge, and software engineering skills. But the world has changed a lot since that article’s publication in October 2012. The hype is over and data science has become standard in most business operations. So, if the data scientist who can do “everything” is an illusion of the past, what then, can we expect from the data scientists of tomorrow? Here, we’ve outlined nine trends we see shaping the future of data science.
Trend 1: “Data Scientists” Become Domain Specialists
The title “data scientist” has become meaningless. Being able to build solutions with data science does not make the difference. The domain makes the difference. Take chatbots, for example. New specialists call themselves trainers or cultural AI specialists, not data scientists. This specialization trend continues in all areas of application. You have to understand something about supermarkets to be able to accurately predict which products should be included in the bonus. If you want to be a good data scientist, you have to dive into your domain. Only then can you make a difference.
Trend 2: Data Scientists Become Machine Learning Engineers
Data Scientists are increasingly retraining to become Machine Learning Engineers because they have to solve different problems. How do you build solid solutions? How do you get these into production? How do you maintain them? The focus was first on finding the right solutions, now it’s about building the solutions correctly. Data scientists are realizing that other skills are needed to add value and are moving towards engineering.
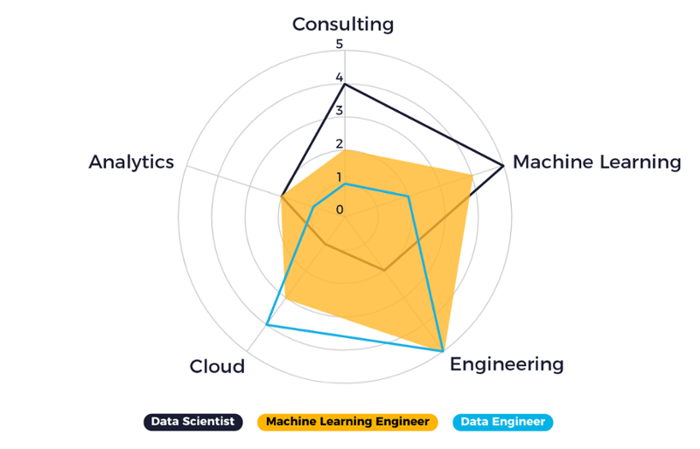
Trend 3: Companies Seek Specialists
Not only do data scientists see that their role is changing, organizations see it too. Companies understand that it is better to look for specialist data scientists than generalists. Bol.com found better candidates for logistics teams after they modified the vacancy and explicitly stated that a background in operations research was desired. Gone are the days of job postings with long, divergent lists of requirements. Companies need specialists with specific experience in a specific domain, technology, or application.
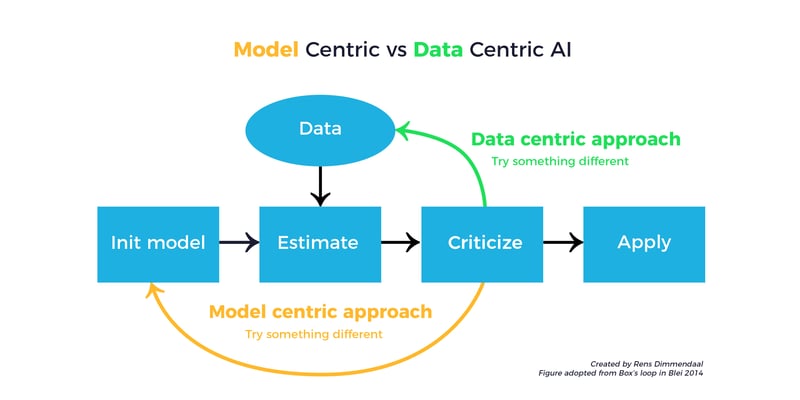
Trend 4: Data Makes the Difference — Not Models
The focus is shifting from the search for better models to better data. Many of the big tech companies have state-of-the-art models that are made with more data, computing power, and knowledge than most companies have at their disposal. These models are often publicly available, so where else can you make a difference? With data that is more specific and better. To build a chatbot for mortgages, you need data exclusive to a specific bank, for example. More text, per se, won’t do. Better models won’t make Tesla’s Autopilot better in winter. It needs images of snow-covered stop signs. Models are so good that data is the bottleneck and competitive advantage. So focus on that.
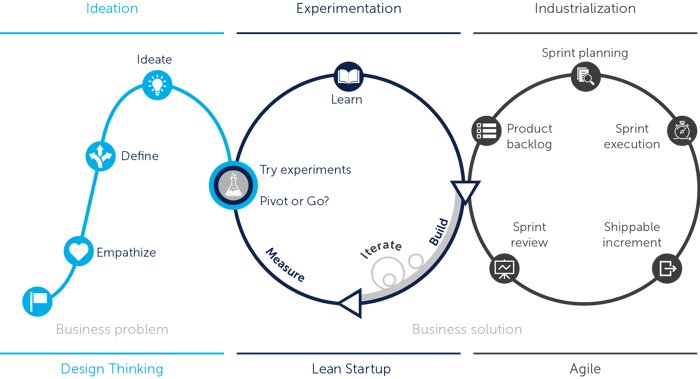
Trend 5: Fewer Experiments, More Creative Thinking
The days of lengthy experiments are over. We now have a better understanding of how to use data science. The demand for companies at the start of their AI Maturity Journey has changed. Where the question was once, “How can we use data science for our problems?” it is now, “How do we best solve our problems?” Take chatbots, for example. You can waste money collecting data to answer all your customers’ questions. Or, you can find the right user experience by, for example, referring to the search functionality or the help desk. Which is better? Design thinking with interviews yields users more than experimenting with models.
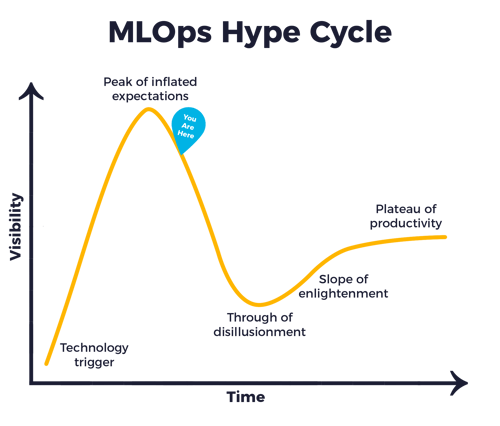
Trend 6: The MLOps Hype Continues
Just as big data was a hype ten years ago, and data science five years ago, MLOps is a hype. Despite all the noise around this theme, it still requires too much customization to get a data science solution into production. In addition, the fragmentation in the market is enormous. There are hundreds of MLOps-like tools that solve different problems. Tracking experiments, registering models, automatic retraining, labeling data: each tool does something different. Everyone has a different view of MLOps. Just like everyone had a different view of big data and data science. It will take a few more years before we really understand MLOps.
Trend 7: More AI Use, Less Build-It-Yourself
Our use of AI will continue to increase, and it won’t require building anything. Photo apps already recognize what’s in your photos — all you need to do is search for the text ‘baby’ and the app shows you all of your baby photos. The keyboard on your phone not only gives spelling suggestions for the text you’ve already typed but also suggestions for the next words you need to type. Software developers can integrate photo recognition into their products without machine learning knowledge. Analysts train chatbots with Google Dialog Flow without programming. Designers use AI in RunwayML to change wallpapers without having to green screen. AI is becoming a ready-made toolbox that anyone can use.

Trend 8: From Creation to Curation
Despite the decline of data science “hype,” there are still plenty of things happening to get excited about.
For one, the momentum is now in unstructured data, versus the tabular data from which data science originated. This means that applications with audio, text, and images are easier to build than those with relational data.
Also, generative AI is now changing the role of humans from creator to a curator. For example, you don’t need a designer for a picture of an avocado chair, just ask DALL-E to generate pictures of it and select the best for yourself.
Trend 9: Data Engineering Reinvents Itself
Data engineering arrived at the same time as data science and is changing in the same ways. Specialists such as analytics engineers, machine learning engineers, and cloud engineers are stepping into the former generalist “data engineer” role.
Once very sexy for all the hype, the data science, and data engineering professions are both changing and specializing— for the better. A data scientist 2.0 doesn’t focus on the model but moves towards the domain, expanding their skillsets to include consulting, or engineering, with deep specializations.
Re-skill yourself to specialize as tomorrow’s Data Scientist?
Make the difference and prepare for the shifts in your career future by following our Analytics Translation & Machine Learning Engineering training courses.
Go to our training courses overview >>